![]()
Last Modfified: 2022-01-31
Note: This article is a high-level discussion of a technical nature (in comparison to other articles). We keep the discussion somewhat abstract but it may still prove difficult to follow.
As eluded to in the previous general update, we are making awesome progress since the last update over the Christmas period. One of the projects we will discuss today is the concept of a balance engine and some of the work that has happened around this.
In the beginning, there were robot dogs…
Video: RoboCup Dog platform in Japan (2009).
Dogs are great as an initial platform - they are stable and cute 1. Initial problems can be addressed with respect to team play, vision, communication, locomotion, etc, whilst offering fun and novel games for the public to engage with.
Unfortunately At some point it was decided that in order to achieve the goal of robots vs people in 2050, they must be bipedal. In 2013, the Bold Hearts decided to switch from a successful run in the simulation league and enter into the humanoid league, which consists of hardware!
Turns out, bipedal walking is hard.
Normally, for open-loop humanoid walking, we would have the open-loop walk send motor commands without any feedback. This worked well for flat surfaces with some walk engine parameter tweaking, and was appropriate in the domain space for quite some years. This in turn gave teams time to work on other advancements, such as vision and localisation.
Video: Bold Hearts DarwinOp player using an open-loop walk engine on a flat surface (2013).
This was never the end-goal though, and some years ago the challenge of walking was made more difficult with the additional of artificial grass. This made the challenge of humanoid walking much more difficult. For the first year of this rule change, very few teams could walk reliably towards the ball. Of course, teams arose to the challenge and in the next year most teams could walk somewhat reliably.
Video: Bold Hearts (modified) DarwinOp player using an open-loop walk engine on artificial grass (2018).
As can be seen, the Bold Hearts and Electric Sheep teams (amongst others) have utilized open-loop walk engines to achieve limited stability walking on artificial grass. Typically this would involve tweaking per-robot walking parameters for the particular field we intend to play on. We found that as the robots became larger and their centre of mass was heightened, the issue of stability became much more difficult.
Video: Electric Sheep player using an open-loop walk engine on artificial grass (2020).
As some teams find moderate success in continuing to tweak their walk parameters, other teams turned to tried-and-true existing methods such as zero moment point (ZMP). ZMP is quite an old well-tested approach and makes the assumption that you are able to calculate centre of pressure (CoP), which can then be abstracted to centre of mass (CoM), which is projected to be always within the ‘support polygon’ (an area defined by the placement of the feet). ZMP works well, and in theory could allow for behaviours such as walking, running, and even jumping - although there has so far been limited success in these behaviours (at least within the league).
There are several challenges we face in the RoboCup humanoid league that differentiate us from other research approaches:
Going further, ZMP only really solves behaviours where a support polygon can be well defined. What if, for example, you wanted to do a flip, perform actions on uneven or unknown terrain, etc? Modified versions of ZMP could in theory handle much more complex scenarios, but these solutions become more complex and much harder to define.
What we are beginning to ask for is a motion engine, an engine that can solve arbitrarily difficult motion tasks 2. This remains the goal of future work, so for now we work on a subset of this problem, which is an adaptive balance engine (ABE).
The intention of ABE is to take the suggestion of an open-loop walk engine, adapt it in a way that provides stability, and then send the motor commands. This does not rely on foot sensors, we do not provide any parameters to the walk engine and theoretically we are not bound by the idea of a support polygon, allowing for momentary instability if required.
We intend to publish more details about this approach at a later date.
Our initial experiments were conducted using the OpenAI Gym cartpole problem, where the agent has the ability to select left or right in each time step depending on some observed state, which includes the cart position, velocity, pole angle and pole velocity. Simulations end when the agent falls outside of some defined bounds.
Other approaches 3, mostly consisting of reinforcement learning (RL) are slower to learn than our ABE approach. Most RL approaches appear to be based on DeepMind’s DQN model from 2015. Our approach is somewhat more computationally expensive, but yields very competitive results.
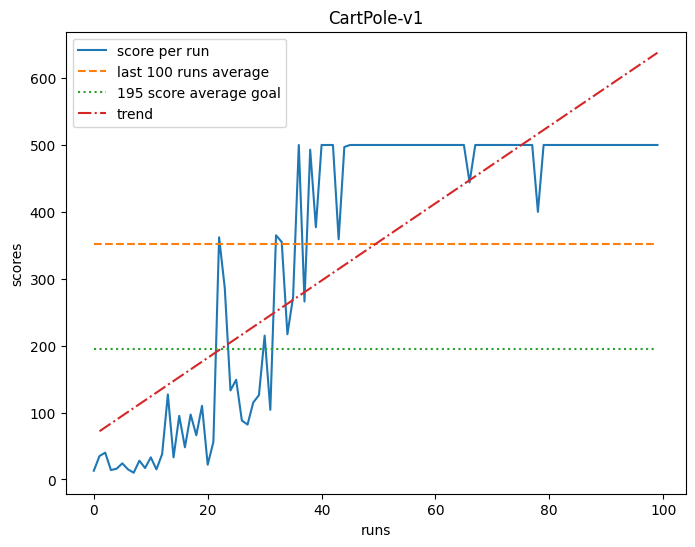
As you can see, it takes approximately 40 experiments for the agent to ‘solve’ the problem maximally with a consistent score of 500 4.
Note: Due to the implementation, there is a 1% chance that the agent takes a random action. This is for the purpose of training.
With the initial results showing promise, we now move into the humanoid simulation environment created by the Bold Hearts. Their platform is based on ROS2, which offers some nice abstractions and allows for code sharing. This allows us to flesh out the concept whilst minimizing damage to real hardware, as well as offering the ability to pre-train the algorithm and minimize time spent on hardware.

(All going well) Going forwards, we intend to explore this research further with the intention of deploying it in Bangkok, Thailand, for the 2022 RoboCup World Cup.
Keep tuned for future updates!
Aesthetically pleasing robots are quite important, especially as by design these competitions are conducted with lots of public engagement.↩︎
This is the subject of a high-level discussion journal paper.↩︎
Note: We only discuss those that have released their source, as the cartpole problem is technically optimally solvable.↩︎
A score of 500 is far better than is required, the ‘win’ scenario is set to 195.↩︎